
【GASでスクレイピング③】実際の使用例レシピを取り出してみた。
マクロ+IE → GAS+スプレッドシート
に変更していくということとで、
今回は、
GASを用いて実際に使用できるプログラミングを作成しました!
いつも、食べたいものある?といわれて困るので、
キッコーマンさんのホームページから、ランダムでレシピを引っ張ってこれる
ようにしています。
①②で紹介したhtmlの情報を取得、そこから必要な情報だけ読み解く
という方法を実践したものになりますので、
是非ご参考にください。
サンプルシートを紹介
サンプルシートを下記に紹介します。
レシピの材料、作り方を順次取り出してくるプログラミングになります。

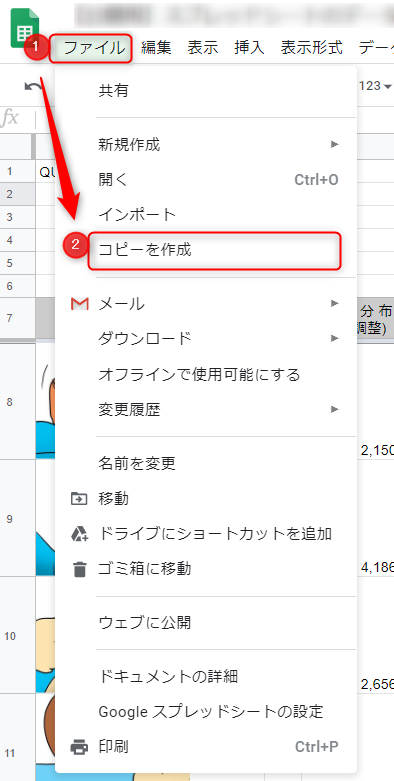
そのままですと閲覧のみ可能になっていますので、
ファイル→コピーを作成で、自分のスプレッドシートにコピーを作成してください。
コード紹介
では、さっそくコードを紹介していきたいと思います。
コードは、
①ランダムにレシピのURL作成
②UrlFetchApp.fetch(url) でurlの情報を抜き出し
③class要素の名前など、キーとなる情報を正規表現で抜き出しitemに代入
④innertextのみにするためにindexOfで文字数を確認
⑤.substringで間の文字列を取り出す
を繰り返す構成になっております。
function myFunction5() {
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('実行');
for(var z=1;z<=10;z++){
SpreadsheetApp.getActiveSpreadsheet().toast(z+'/10', '進捗',10);
//セルに存在する最後の行
lastY = sheet.getLastRow()
lastX = sheet.getLastColumn()
var url = sheet.getRange(2, 3).getValue();
sheet.getRange(lastY+1,3).setValue(url)
Logger.log(url)
var options = {
"muteHttpExceptions": true, // 404エラーでも処理を継続する
}
var response = UrlFetchApp.fetch(url, options);
var html = response.getContentText('UTF-8');
var fromText = sheet.getRange(3, 3).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = [0,1];
var item = html.match(itemRegexp);
var items = [];
if(html.match(itemRegexp)===null){
sheet.getRange(lastY+1, 4).setValue("該当なし")
}
else{
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
sheet.getRange(lastY+2, 4, items.length, 1).setValues(items);
var fromText = sheet.getRange(3, 4).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
var items = [];
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
sheet.getRange(lastY+2, 5, items.length, 1).setValues(items);
var fromText = sheet.getRange(3, 5).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
var items = [];
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
sheet.getRange(lastY+2, 6, items.length, 1).setValues(items);
var fromText = '<title>';
var toText=' キッコーマン'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
var items = [];
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
//.replace(fromText,'')
//.replace(toText,'');
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('のレシピ');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
sheet.getRange(lastY+1, 4, items.length, 1).setValues(items);
var imageY=lastY+1
sheet.getRange(lastY+2,3).setValue('=image(LEFT(C'+imageY+',50)&"img/"&mid(C'+imageY+', 51,8)&".jpg")')
// sheet.getRange(lastY+2,3,5,1).merge();
}
}
}
簡単に説明
コードの内容を簡単に説明していきます。
HTMLの情報の抜き出し
UrlFetchApp.fetch(url);
でresponseに情報を格納し、
e.getContentText()
で、文字列としてエンコードされたHTTP応答のコンテンツを取得します。
// The code below logs the HTML code of the Google home page.
var response = UrlFetchApp.fetch("http://www.google.com/");
Logger.log(response.getContentText());
class要素などをキーに情報を抜き出し
上記で得たテキストデータから、必要な情報を抜き出します。
抜き出す方法としては、「正規表現」で抜き出しています。
少し難しいので、
「/ 文字列A .*? 文字列B /」
とすると、文字列A~文字列Bとなっている文字列を抜き出すことができると思ってください。
var fromText = sheet.getRange(3, 3).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
これで、
fromtext ~ totext
の文字列をitem配列に代入することができます。
今回は、fromtextは任意、totextは「<」に固定し、文字列を抜き出しています。
イメージとしては、
<dd><p class="amount">150g</p></dd>
というテキストデータから
amount ~ <
となるテキストを検索し、
item に 「 amount">150g< 」を代入しています
抜き出したデータから必要な部分だけ抜き出し
抜き出したデータは、
item = amount">150g<
というように、いらない文字列が残っています。
そこで、
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
を用いて、「>」「<」の間のテキストだけを抜き出し、
2次元配列itemsに代入していっています。
そして結果を、
SpreadsheetApp.getActiveSheet().getRange(5, 4, items.length, 1).setValues(items);
にて、セルに張り付けることで、完了です。
その他ポイント
404エラーでも処理を実行するために、下記コードを追加しています。
var options = {
"muteHttpExceptions": true, // 404エラーでも処理を継続する
}
var response = UrlFetchApp.fetch(url, options);


コメント欄