【GASでスクレイピング②】知りたい情報をclassなどから取り出す。
ついについにIEが使えない時代が訪れるということで、
ウェブスクレイピングを
マクロ+IE → GAS+スプレッドシート
へ変更していく必要があると感じています。
そこで今回は、GASで行うウェブスクレイピングの準備をしていきたいと思います!
ウェブスクレイピングのやり方
まずは、私の行う、ウェブスクレイピングの基本的なやり方について解説していきたいと思います。
私の行うウェブスクレイピングは、
①特定のサイトのHTMLの情報を取り出す
②そこからcalssやidなどの情報から、必要な情報だけ抜き出す
という方法です。
もう少しかみ砕いて説明すると、
①サイトのページの情報をテキストとして取り出し、
②特定の文字列をキーにして、その間の文章を抜き出す
という方法です。
今回は、その中でも
②特定の文字列をキーにして、その間の文章を抜き出す方法
を紹介していきたいと思います。
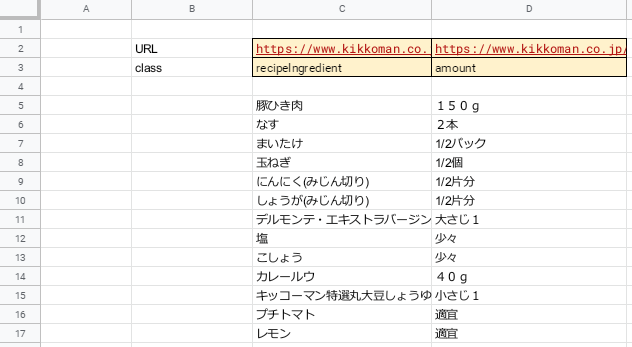
サンプルシートを紹介
サンプルシートを下記に紹介します。
サンプルシートでは
・2行目C列,D列に入力されたURLの情報を取り出し
・3行目C列,D列に入力された検索文字列
「recipeIngredient」「amount」に該当するの情報を抜き出し、
・5行目以下に書き込む
プログラムとなっております。

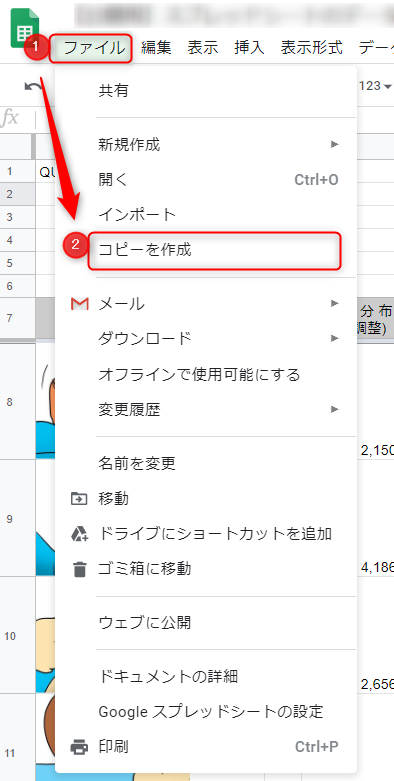
そのままですと閲覧のみ可能になっていますので、
ファイル→コピーを作成で、自分のスプレッドシートにコピーを作成してください。
コード紹介
では、さっそくコードを紹介していきたいと思います。
コードは、
①UrlFetchApp.fetch(url) でurlの情報を抜き出し →このサイトを参考
②class要素の名前など、キーとなる情報を正規表現で抜き出しitemに代入
③innertextのみにするために無理やり「>」「<」の間の文字列をとっています。
という構成になっております。
function myFunction5() {
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('実行');
var url = sheet.getRange(2, 3).getValue();
var response = UrlFetchApp.fetch(url);
var html = response.getContentText('UTF-8');
var fromText = sheet.getRange(3, 3).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
var items = [];
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
SpreadsheetApp.getActiveSheet().getRange(5, 3, items.length, 1).setValues(items);
//2個目
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('実行');
var url = sheet.getRange(2, 4).getValue();
var response = UrlFetchApp.fetch(url);
var html = response.getContentText('UTF-8');
var fromText = sheet.getRange(3, 4).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
var items = [];
Logger.log(item.length)
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
SpreadsheetApp.getActiveSheet().getRange(5, 4, items.length, 1).setValues(items);
}
簡単に説明
コードの内容を簡単に説明していきます。
HTMLの情報の抜き出し
UrlFetchApp.fetch(url);
でresponseに情報を格納し、
e.getContentText()
で、文字列としてエンコードされたHTTP応答のコンテンツを取得します。
// The code below logs the HTML code of the Google home page.
var response = UrlFetchApp.fetch("http://www.google.com/");
Logger.log(response.getContentText());
class要素などをキーに情報を抜き出し
上記で得たテキストデータから、必要な情報を抜き出します。
抜き出す方法としては、「正規表現」で抜き出しています。
少し難しいので、
「/ 文字列A .*? 文字列B /」
とすると、文字列A~文字列Bとなっている文字列を抜き出すことができると思ってください。
var fromText = sheet.getRange(3, 3).getValue();
var toText='<'
var KENSAKU = fromText + '.*?' + toText
var itemRegexp = new RegExp(KENSAKU,'g');//gで全て
var item = html.match(itemRegexp);
これで、
fromtext ~ totext
の文字列をitem配列に代入することができます。
今回は、fromtextは任意、totextは「<」に固定し、文字列を抜き出しています。
イメージとしては、
<dd><p class="amount">150g</p></dd>
というテキストデータから
amount ~ <
となるテキストを検索し、
item に 「 amount">150g< 」を代入しています
抜き出したデータから必要な部分だけ抜き出し
抜き出したデータは、
item = amount">150g<
というように、いらない文字列が残っています。
そこで、
for (var i = 0; i < item.length; i++) {
var itemURL = item[i]
var S_num = itemURL.indexOf('>');
var E_num = itemURL.indexOf('<');
var itemURL = itemURL.substring(S_num+1, E_num);
items.push([itemURL]);
}
を用いて、「>」「<」の間のテキストだけを抜き出し、
2次元配列itemsに代入していっています。
そして結果を、
SpreadsheetApp.getActiveSheet().getRange(5, 4, items.length, 1).setValues(items);
にて、セルに張り付けることで、完了です。


コメント欄